变量是所有程序的基础,类型告诉编译器数据代表什么意思以及可对此数据执行的操作。例如int类型的数据可以执行加减法,而bool类的数据就不能进行加减法。这些都是数据类型规定的。C++语言定义了几种基本类型:字符类型、整型、浮点型等,除此之外,C++还提供了可用于自定义类型的机制,如可自定义类类型。变量和类型是C++语言基础的概念,同时也是编程中最容易疏忽的地方。本章将介绍变量和类型的相关概念和编程陷阱。通过本章的学习,希望能帮助你对变量和类型有更深刻的认识。

计算机是如何存储变量的
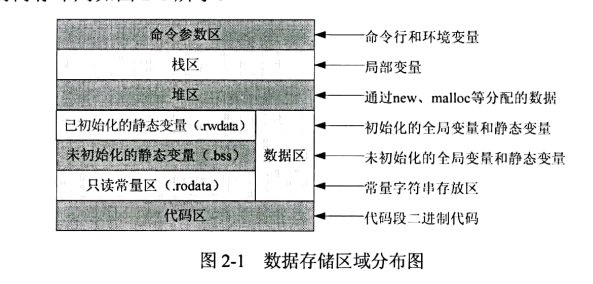
众所周知,计算机界一直存在这样一个共识:编程=数据+算法。从这个共识可以看出,程序其实就是实现数据的处理,及解决如何处理数据的问题。高级语言能处理的数据一般都存放在内存中,程序如何高效地处理数据,这与数据在内存中的存储情况息息相关。特别是C/C++语言,要想运用好它,就必须对数据在内存中放置及存放格式有详细的掌握。数据在内存中的放置包括两个部分:一是数据放置的位置,二是数据放置的格式。数据放置的位置,即数据存储的区域。C++可执行程序的数据存储区域可分为只读数据区、全局/静态存储区、自由存储区、栈区和堆区5种。下面这段代码就涵盖了所有数据存储区域类型
就涵盖了所有数据存储区域类型。int g_init var =100; // 初始化的全局变量g_init_var=100int g_uninit var; // 初始化的全局变量g uninit varvoid Func(init) // 输出一个整数到屏幕{printf("%d\n", i);}int main(void){static int static var= 101; // 初始化的局部静态变量static_var=101static int static var2; // 未初始化的局部静态变量 static var2intnNumber=1; // 初始化的局部变量nNumber=1intnNumberB; // 未初始化的局部变量nNumberB// 输出 static_var、static_var2、nNumber、nNumberB 的和到屏幕Func(static var+static var2+nNumber+nNumberB);char *pszstrLG="liuguang"; //指向常量 liuguang 的局部指针变量 pszstrLGchar *pszStr2=new char; //指向堆区的内存的局部指针变量 pszSt2delete pszStr2;int*pnNumber=static_ cast<int*>(malloc(sizeof(int)); //分配在自由存储区的pnNumberfree(pnNumber);return 0;}
●只读数据区:存储常量和恒值。例如,上述代码第 019 行的字符串 liuguang 就分配于只读数据区。存储于只读数据区的变量一般不允许修改。当然所有的数据都是相对的,可通过一些非正常手段修改只读数据区。
●全局/静态存储区:全局/静态存储区主要存储全局变量和静态变量。在C语言中,全局变量又分为初始化的全局变量和未初始化的全局变量,初始化的全局变量和静态变量存储在data区,未初始化的全局变量与静态变量存储在相邻的 bss区,而在C++里面没有这个区分,它们共同占用同一块内存区。例如,上述第001、002、011、012行代码中所涉及的变量均分配在全局/静态存储区。
●自由存储区:自由存储区是指 CRT(C 运行时库)通过 malloc、free 函数管理的内存。在部分编译器的实现上,自由存储区和堆两块内存都是同一种管理方式,所以可统称为堆区。例如,上述代码第 023行 pnNumber 变量对应的内存块即自由存储区。
●栈区:栈区中存储的数据由编译器自动分配释放,主要存放函数的参数值、局部变量值等。其操作方式类似数据结构中的栈。栈区在分配数据时,地址自动对低地址增长。在程序执行过程中,栈可以动态地扩展和收缩。一个函数的栈空间大小一般为 2MB。当然函数的栈空间大小可通过设置编译选项修改。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。用户栈在程序执行期间也可动态地扩展和收缩。例如,上述代码段中第014、015行的nNumber 和 nNumberB就分布于栈区中。
●堆区:堆区指那些由 new 分配的内存块,编译器不负责它们的释放。上述代码中第 020 行 pszStr2所指的内存块就分配在堆区。分配在堆区的变量由应用程序去控制,一般一个 new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆区可在程序运行过程中,根据需要动态地申请和释放。堆区的这种操作特性可节省数据存储空间。
注意:堆区分配数据虽具有节省空间、使用方便灵活的优点,但并不是说所有的变量都应该分配在堆区。堆区上分配数据有两个风险:
(1)频繁分配和释放内存会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低,
(2)分配的数据如果没有释放,很容易造成内存泄露。这是在C++初学者中普遍存在的问题.
C++中的所有数据都通过这5种数据类型实现数据的存储和分配。这5种数据存储类型的内存布局如图2-1所示。
介绍完数据的存储位置,接着介绍数据的存储格式。因为任何数据都是以一定格式存储的,只有这样才能被CPU 及编译器识别,所以了解数据的存储格式也是掌握数据类型较为关键的部分。C++内置的数据类型有整型和浮点型,编程人员可自定义的类型有class、struct 等。
1.整型值
整型值是程序员处理和操作最多的数据,表示整数、字符型和布尔值算术类型合称整型。
字符类型有两种:char 和wchar_t。char 主要存储机器基本字符集中任何字符相应的值,因此 char 通常是单字节的。wchar_t 类型用于存储扩展字符集合,由于扩展字符集中的字符不能用一字节表示,所以wchar_t通常是双字节的。
int、short、long 类型都表示整型值,不同之处是存储变量所占的内存空间大小不同。short类型一般为半个机器字长,int 占一个机器字长,long占一个或两个机器字长。
整型存储说明:
整型与其在计算机存储中的表示方式密切相关。计算机以位序列存储数据,每一位存储0或1,通常以8位块作为一字节,32位或4字节作为一个“字(word)”。
大多数的计算机将存储器中的一字节和一个称为地址的数关联起来。要让存储器中某一地址的字节有意义,必须知道存储在该地址的值的类型。
bool类型表示真值 true 和 false。可将算术类型的任何值赋给 bool 对象,0 值代表false,非 0 代表 true。除 bool 类型外,整型可以是有符号的(signed),也可以是无符号的(unsigned)。整型 int、short、long 默认都是带符号型。整型以二进制补码形式存储,其中正数等于原码,负数等于反码+1。例如,100的原码为 0x64,在内存中存储的补码为 0x64;-1的原码为0x01,反码为0xFE,在内存中存储的补码为0xFF。表2-1列出了所有整型值的类型、字节长度和可能的取值范围。
表2-1 整型数据取值范围
| 整型类型 | 占用字节 | 取值范围 |
| (signed) char | 1 | -128~127 |
| unsigned char | 1 | 0~255 |
| (signed) short | 2 | -32768~32767 |
| unsigned short | 2 | 0~65535 |
| (signed) long | 4 | -2 147 483 648~2 147 483 648 |
| unsigned long | 4 | ~4 294 967 295 |
| (signed) int | 4 | -2 147 483 648~2 147 483 648 |
| unsigned int | 4 | 0~4 294 967 295 |
| bool | 1 | true/false |
2.浮点类型
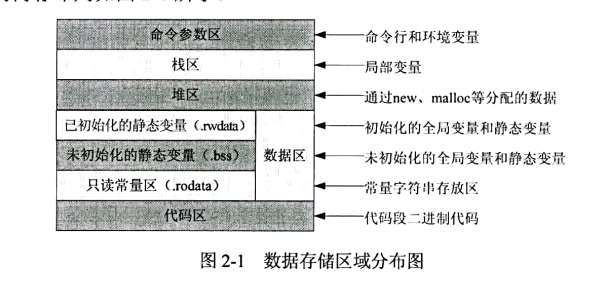
C++对浮点类型的数据采用单精度类型(float)和双精度类型(double)存储.float数据占用32bits,double 数据占用64bits。无论是单精度还是双精度,在存储时,都分为3个部分:(1)符号位(Sign)占用1字节,0代表正数,1代表为负数;(2)指数位(Exponent),用于存储科学计数法中的指数数据,并且采用移位存储;(3)尾数部分(Mantissa)。
float 的存储格式如图 2-2 所示,指数位采用移位存储,偏移量为 127。采用图 2-2所示的 float 数据十进制数值等于(-1)ign *(1.Mantissa)*2(Exponent-llllll)。
32bits
64bits
浮点型格式说明:
●浮点数计算时,sign、Mantissa 和 Exponent 必须为二进制形式。
●对于指数部分,由于指数可正可负,对于float 类型8 位的指数位能表示的指数范围就应该为:-127~128。为了保证指数位为正数,所以指数部分的存储采用移位存储,存储的数据为元数据+127。对于 double 类型11 位的指数位能表示的指数范围就应该为:-1023~1024。为了保证指数位为正数,所以指数部分的存储采用移位存储,存储的数据为元数据+1023。
举例说明:
(1)8.25f的存储形式:首先将 8.25 进行二进制科学计数表示为1.0001*2b。按照上面单精度浮点数存储方式,符号位为0,表示正数;指数位为10000010B =11B+1111111B;尾数为0001 。所以8.25f在内存中的存储形式为01000001000010000000000000000000B。
(2)120.5double 类型的存储形式:首先将120.5 进行二进制科学计数表示为1.1101101*2110b。按照上面双精度浮点数存储方式,符号位为 0,表示正数;指数位为100 0000 0101B=110B+1111111111B;尾数为 1101101。所以120.5在内存中的存储形式为0100000001011101101000000000000000000000000000000000000000000000。
最后再介绍一些编程中经常遇到的陷阱,主要包括截断、类型转换等。截断是C++和 C变量赋值最容易出现的陷阱。截断往往隐含着赋值越界的错误,这种错误会产生什么后果取决于所使用的机器。比较典型的情况是数据越界而变成很大的负数。如果实现代码:
char cValue --128;printf("cValue -%d",cValue);
这段代码的本意应该是输出“cValue =128”,但实际上输出的却是“cValue =-128”,这就是C++语言具有的数据截断陷阱。产生这种现象的主要原因是128初始化cValue时,cValue在内存中的对应数据为10000000B(对应十进制128)。由于 10000000B为补码形式,转换成原码即是-128。
除了截断陷阱以外,其他经常碰到的陷阱还有强制类型转换,如把一个int 型变量转换为一个char 变量会伴随着数据的丢失。
假设定义一个int 型变量 iValue = 0x2345;,同时又定义了一个char 变量cValue 并初始化cValue=(char)iValue;,最后 cValue 的值会是多少是无法确定的。cValue 的值与字节序有关系,小端字节序下cValue 等于 0x45,大端字节序下cValue 等于 0x23。所以在实际编程过程中,应尽量避免非提升强制转换。因为非提升强制转换一般会伴随着数据精度的损失,严重情况下会出现模棱两可的现象。
请谨记
●变量在不同语境下,其分配内存区域是不同的。静态变量和全局变量一般分布在全局/静态存储区,函数的参数和变量一般分配在栈中,new 和malloc 申请的数据一般分配在堆中。
●变量在定义和初始化时,一定要注意其取值范围,以防出现数据截断异常现象。同样,数据在使用过程中应禁止降级强制转换,这种转换一般会降低数据的精度,严重时会出现模棱两可的问题。





















